The Challenges: Overcoming Traditional DR Pain Points
Imagine your team is running Kubernetes and SUSE Virtualization clusters, and you’re struggling to find a disaster recovery solution that meets your needs for low RPO and RTO. You’re likely dealing with traditional solutions that are not only prohibitively expensive and complex, but also lead to limited flexibility and vendor lock-in. For large hybrid and edge environments, constraints on bandwidth, cost, and supportability make it even more difficult to find an appropriate solution, causing a constant sense of anxiety.
The Solution: CloudCasa and SUSE Storage
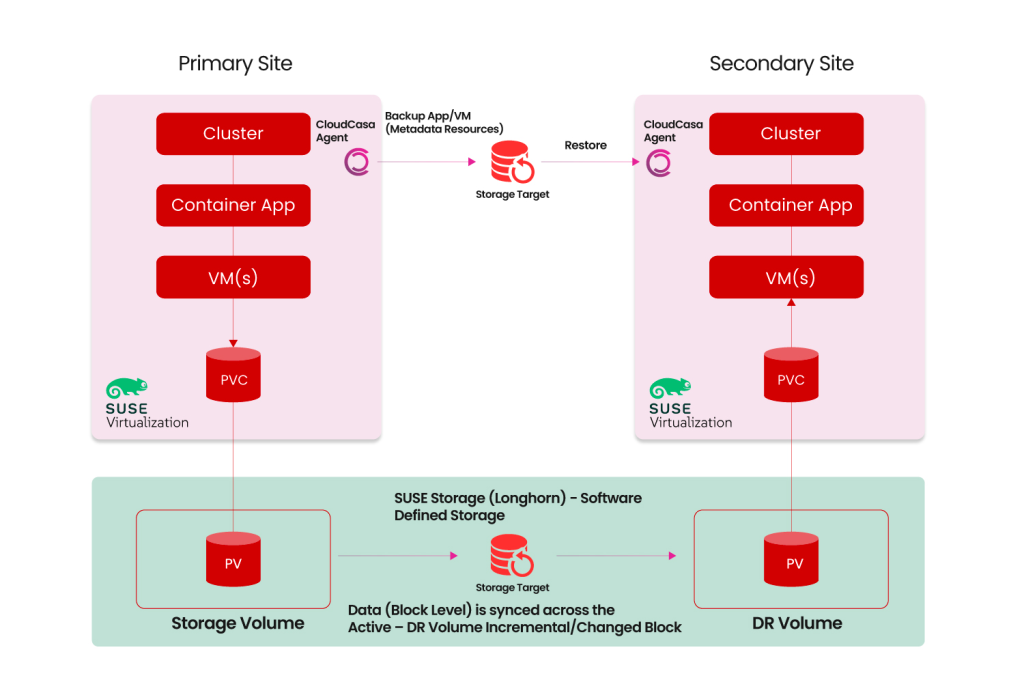
The CloudCasa and SUSE Longhorn solution eliminates much of the cost and complexity by aligning application recovery with storage-based volume replication.
CloudCasa protects Kubernetes application configurations, metadata, and associated Kubernetes resources. Longhorn maintains disaster recovery volumes at the destination cluster, which are periodically updated from the source cluster.
In the event of a DR failover, CloudCasa restores the application and automatically maps and activates the corresponding Longhorn DR volumes. This ensures that persistent volumes are instantly available to the application without manual intervention.
The result is a streamlined, repeatable workflow that minimizes downtime, reduces the amount of data that must be transferred during recovery, and removes the need to duplicate replication functionality.
Understanding RPO and RTO
- A recovery point objective (RPO) is the amount of data loss that can be tolerated in the event of a failure, measured in time. For example, if you are willing to lose at most the last 30 minutes worth of activity in a given system in the event of a disaster, the RPO for it would be 30 minutes.
- A recovery time objective (RTO) is the maximum amount of downtime that can be tolerated for an application. For example, if an application must be back online within 60 minutes after a failure, the RTO would be 60 minutes.
It can be tempting to aim for near-zero RPOs and RTOs, but this can cause the cost of a system to increase exponentially. The CloudCasa + Longhorn solution is capable of providing RPOs and RTOs in the 10 minutes to 1 hour range, which is sufficient for even business-critical applications in most industries. It can do this at a fraction of the price of other solutions.
How It Works: The Seamless Workflow
- Preparation: Longhorn DR volumes are configured to ensure volume replication between your source and destination clusters. The replication frequency should be based on your RPO.
- Protection: CloudCasa runs periodic application-level backups, capturing Kubernetes resources and metadata, while relying on Longhorn to handle persistent volume replication. The frequency of CloudCasa backups should also be based on your RPO. PV data can be excluded from CloudCasa backups or preferably backed up less frequently to protect against logical failures.
- Disaster Recovery: In a disaster recovery scenario, CloudCasa restores the application resource data, referencing the existing Longhorn DR volumes. The DR volumes are automatically activated and made available as persistent volumes on the destination cluster as part of the restore. Since the amount of data restored by CloudCasa is very small, the recovery process can be completed, and the applications made available within minutes.
The result is a seamless recovery workflow where Longhorn delivers the data, CloudCasa delivers the application state, and together they ensure application-consistent recovery on the destination cluster.
Next Steps
Ready to streamline your disaster recovery today?
CloudCasa and SUSE Longhorn now offer a disaster recovery solution that brings applications and data online faster, with less complexity, and at a lower cost. It’s purpose-built for modern, distributed environments where speed and reliability are essential.