Most Kubernetes users understand the complexity involved in managing multiple Kubernetes clusters, especially when those clusters are hosted in hybrid cloud or multi-cloud environments. There are many reasons why a Kubernetes user may utilize multiple clusters, and those include development vs test vs production instances, to segregate the work of different teams, projects, or application types, security reasons, or to take advantage of the many scaling benefits of a cloud-managed, or cloud-hosted Kubernetes environment. However, rapid adoption of Kubernetes, multiple disparate environments, and unclear administration often leads to unexpected complexities with configuration drift, security, management and more. These complexities make it more difficult to perform a Kubernetes full stack recovery and take full advantage of the multi-cluster Kubernetes infrastructure and difficult to migrate data across and throughout the environment.
Complexities During Migration of Kubernetes Workloads for a Full Stack Recovery
There are many different reasons why Kubernetes users would want to or need to migrate workloads from one Kubernetes location to another. Perhaps, they want to upgrade their cluster infrastructure and move the data to that new cluster or to new storage. Data may need to be migrated to a new on-premises datacenter or to a different region in the cloud, moved from an on-prem location into the cloud, or even between two different cloud vendors. And finally, your development or DevOps team may want to migrate data for dev/test purposes, like cloning production workloads into a dev or QA environment for testing purposes.
However, migrating, cloning and moving these workloads and their data is not an easy task. Several complexities make these types of projects very difficult.
- Kubernetes workloads involve many moving parts: It is important to remember that there are components like metadata, config maps, and secrets that are stored in etcd, or persistent volume data that prevents the workload from being able to be migrated without also moving those components.
- Segregated Design of Multi-Cluster Environments: By keeping workloads isolated, Kubernetes clusters do not communicate with one another. They may not share a network, and they oftentimes do not share storage. The challenge is presenting that persistent volume or the etcd data so that it can be moved to a different cluster without exposing it to a public network. This obviously becomes even more difficult when a user doesn’t want to recover the entire cluster, but instead just granular workloads. A cross-cluster recovery of this kind is not only extremely tedious and resource dependent, but error prone.
- Preparing a Cluster Recovery Destination: Another thing to keep in mind, whenever we talk about migrating workloads, or restoring Kubernetes clusters, namespaces, etc., we need to consider where is the data being migrated or recovered to. It’s one thing to organize all the components, granular details, and networking particulars, to prepare for a cross-cluster data migration or workload recovery, but identifying and preparing a target destination for those workloads is another beast in itself.
From a disaster recovery scenario, for example, if a local outage occurs and you lose access to your on-premise Kubernetes clusters, or perhaps the entire site is destroyed, how do you quickly and effectively recover that data to another Kubernetes environment in the cloud?
In order for your operations team to recover the missing or corrupted data, there must be a destination cluster available to restore to. To create an entirely new cluster from scratch to be used as the target for the recovered data would take much too long. Because of this, DevOps must utilize stand-by clusters, which sit and wait for a recovery to be required, and restore data to this existing stand-by cluster. The problem with stand-by clusters is that while they wait, doing nothing, they consume cloud resources and cost money.
So then how do you manage workloads and data across this multi-cluster, multi-cloud Kubernetes infrastructure?
Automating Kubernetes Cross-Account and Cross-Cluster Restore
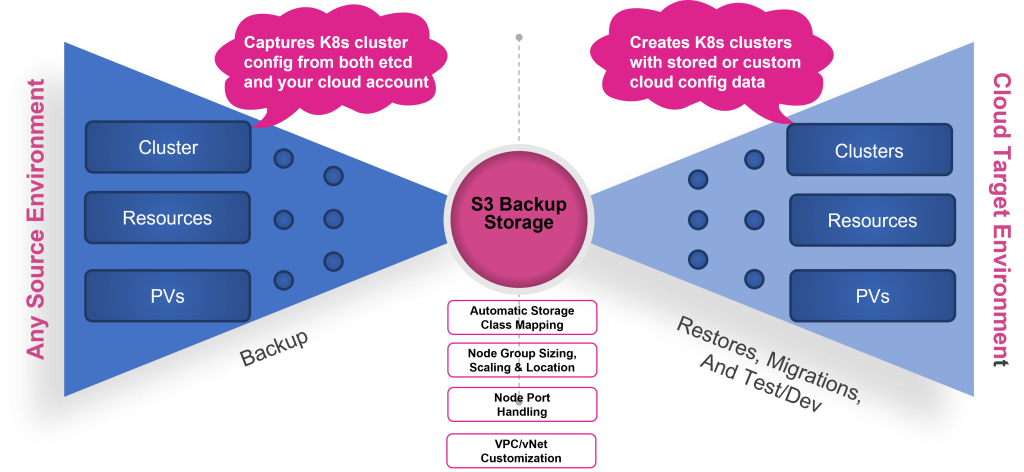
CloudCasa by Catalogic takes the complex task of migrating or restoring Kubernetes workloads across different clusters, infrastructure, or clouds, and provides an intuitive, efficient, and automated solution. CloudCasa is a hosted SaaS backup solution for Kubernetes that allows users to back up their Kubernetes workloads, and then at the cluster level, or at a much more granular level, restore to the original cluster, or to an alternate or new cluster. CloudCasa is the clear industry leader in automation and integration for Kubernetes data protection. Thanks to its integration with Azure Kubernetes Service (AKS), Amazon Elastic Kubernetes Service (EKS), and Google Kubernetes Engine (GKE), this cross-cluster full stack recovery extends to these cloud environments as well. Your development or DevOps team can restore from on-premise environments into the cloud, between different cloud accounts, or different clouds altogether.
When it comes to the complexities mentioned above, CloudCasa’s Kubernetes full stack backup and recovery simplifies the process of backing up not only the persistent volume data and the resource or etcd data, but also the associated cloud configurations and metadata. It then allows that data to be restored to any registered Kubernetes cluster, regardless of resources, CSI driver, cloud-hosted platform, etc. The formerly complex, error-prone process of granular backup and restores is made easy through CloudCasa’s self-service UI.
Also, when it comes to cluster recovery, CloudCasa’s Kubernetes full stack recovery eliminates the need for a stand-by cluster. With its cloud account integration, a CloudCasa backup takes a snapshot of the cloud account configuration in addition to the Kubernetes resources and data. This cloud configuration provides CloudCasa with the ability to spin up a brand new AKS, EKS or GKE cluster, using the cloud configuration information, in real-time during a restore. With this feature, there is no longer a need to have a stand-by cluster waiting to be used as a destination for a restore.
And with CloudCasa’s Any2Cloud functionality, this Kubernetes full stack recovery feature is even more valuable. Any2Cloud allows DevOps to take Kubernetes data backed up from one cloud and restore it to a new cluster in a different cloud provider. It can handle mapping of node ports, storage classes, sizing, and scaling information because of the direct integration with the cloud provider.
Try the Best Kubernetes Backup with Full Stack Recovery
For many reasons, Kubernetes users distribute their workloads across multiple clusters. This may be on-premise, across various cloud-hosted Kubernetes environments, or a mix of both. However, when data is spread out across clusters on different storage, hosted by different providers, with resources that do not communicate with one another, it becomes very difficult to migrate or restore data from one cluster to another.
CloudCasa’s Kubernetes full stack recovery functionality simplifies this process. A new cluster can be spun up on the fly to be used as the destination for recovered data. Your operations team can back up Kubernetes workloads hosted in one cluster and migrate the entire cluster, or granular resources from that cluster, into a different cluster. This saves the hassle and the money that is required to utilize stand-by clusters for restores.
If you would like to learn more about CloudCasa, or if you would like to sign up for free, visit CloudCasa.io. Please also feel free to get in touch with any questions, comments or feedback about CloudCasa and your requirements for cloud native backup