Why Enhance MongoDB Backup and Restoration in Kubernetes Environments?
In this blog, we will guide you step by step through using CloudCasa for MongoDB backup and restoration of NoSQL databases such as MongoDB operating in your Kubernetes environment. Before we begin, let’s have some basic understanding of the database under test. NoSQL databases provide a variety of benefits including flexible data models, horizontal scaling, lightning-fast queries, and ease of use for developers. NoSQL databases come in a variety of types including document databases, key-value databases, wide-column stores, and graph databases.
MongoDB is one such opensource, NoSQL database management platform, and is used by many organizations such as Forbes, Volvo, and Toyota.
Application-consistent database backups are critical in case of disasters, accidental deletion, overwriting, corruption or any other type of data loss. CloudCasa helps restore a database after an outage, and allows the recovery of the data from an earlier point in time. It also helps to meet your company’s compliance and governance requirements.
Following are some requirements for consideration for MongoDB backups in Kubernetes environments:
- Regularly schedule Kubernetes backups to meet recovery point objectives (RPOs)
- Encrypt backup files to protect sensitive data.
- Tamper-proof backups against unauthorized deletion or modification with S3 Object Lock or an API Lock mechanism.
- Store copies of your Kubernetes backups in a separate location, such as in a different availability zone or region, to protect against local or regional disasters.
- Ensure there are application-consistent MongoDB backups by using a backup solution that is application aware.
Setting Up a MongoDB Server in a Kubernetes Cluster
Let’s use Helm for the database creation. Helm is a package manager for Kubernetes that makes it easy to take applications and services that are either highly repeatable or used in multiple scenarios and deploy them to a typical K8s cluster. To get started:
- Download the MongoDB Helm Chart locally.
- Ensure your cluster is using a CSI driver that supports snapshots or another supported storage provisioner. For example, the storageClass “csi-hostpath-sc” on MiniKube. Check this documentation for more information on different CSI drivers as per your requirements.
Use “helm install . –generate-name” to install MongoDB. It will also provide you with further commands to access MongoDB Database.
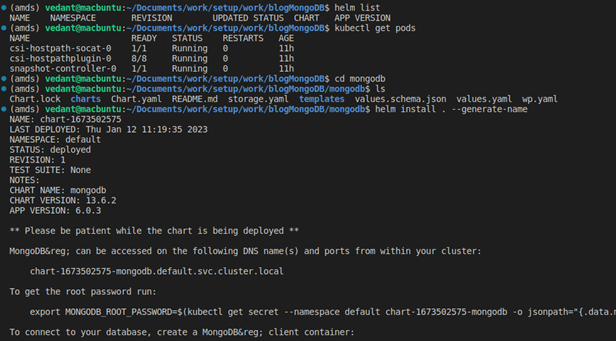
Note: We are using MiniKube for this demo, but CloudCasa supports any managed Kubernetes services such as AKS, EKS, and GKE.
The following screenshot outlines our MongoDB setup:
What are CloudCasa Application Hooks?
Application hooks or App hooks is a feature of CloudCasa that allows users to execute custom code at specific points in the backup and restore process such as pre-backup, post-backup, and post-restore. This can be useful for performing actions that are not supported out-of-the-box by CloudCasa, such as backing up non-Kubernetes resources or integrating with other tools and services.
When performing a backup, you can specify one or more commands to execute in a pod when that pod is being backed up. The commands can be configured to run before Persistent Volumes (PVs) are backed up (pre-backup hooks), or after PVs are backed up (post-backup hooks).
For this blog we will leverage this feature for taking an application consistent snapshot of a Mongo DB. Here the use case under consideration is to quiesce the database while the backup operation is in process.
We can achieve this with a CloudCasa backup job by simply providing a pre-backup App hook that will automatically quiesce write operations and a post-backup app hook that will resume write operations in the Mongo DB.
Using app hooks in CloudCasa is very simple. You can directly use the templates provided by default, or you can customize them based on our needs with very little effort. Once defined, App Hooks can be referenced from backup or restore definitions.
Let us walk you through how one can use App Hooks in CloudCasa while creating a backup!
Installation of CloudCasa on the Kubernetes Cluster
Before we perform a backup, we need to install the CloudCasa agent on the Kubernetes cluster.
- Log in to CloudCasa at https://home.cloudcasa.io .
- From the menu bar, go to Configuration > Clusters.
- Click “Add cluster +” to open the Add cluster pane.
- Fill in the required fields and click “Register”
- Follow the on-screen instructions to install the CloudCasa agent manually or automatically.
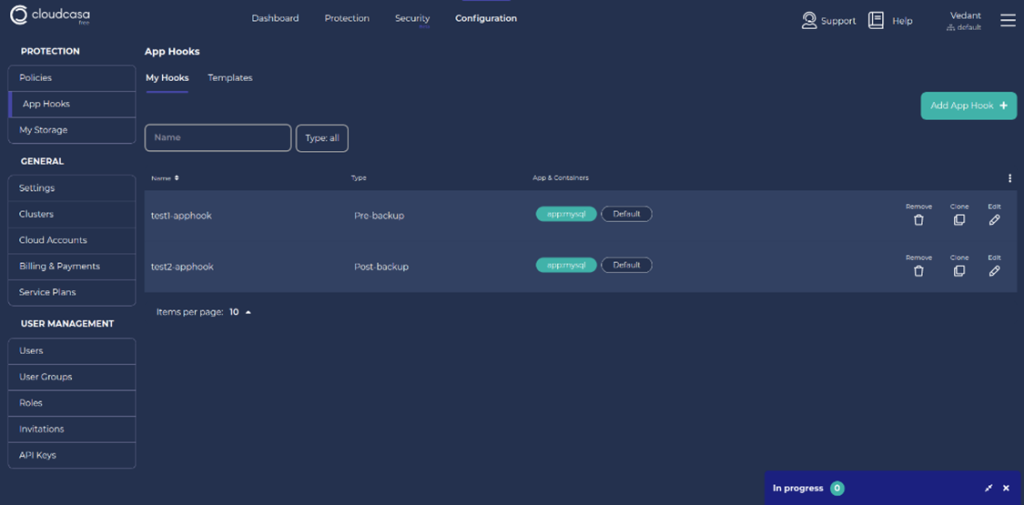
Adding App Hooks in CloudCasa
Add an App Hook so that you can run shell commands on your Kubernetes cluster.
- From the menu bar, open Configuration > App Hooks
- Click Add App Hook + to open the Add App Hook pane.
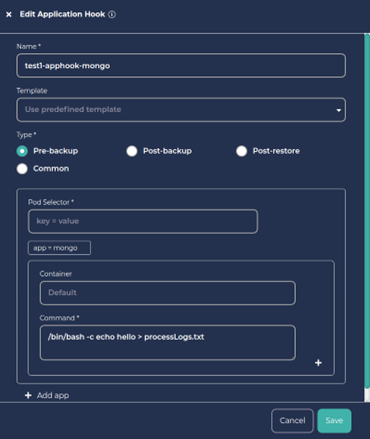
This page consists of 2 tabs which are My Hooks and Templates. CloudCasa provides a few built-in templates to choose from for the ease of customers. In this example as we are using MongoDB and are configuring a pre-backup hook, we’ll choose MongoDB-pre-backup-system-hook. Note that the app hook type Pre-backup is selected automatically.
The template supplies the proper command to flush and lock the database so that CloudCasa can obtain an application consistent snapshot at backup time. In this case, the command is “FLUSH TABLES WITH READ LOCK”. All write access to tables will be blocked and all tables will be marked as ‘properly closed’ on disk while CloudCasa takes a snapshot of the persistent volume.
You can edit the hook command if you wish. For example, to prove to yourself that the hook command is being executed, you could change it to “/bin/bash -c echo hello > processLogs.txt”. This echo command creates a file in the Linux system.
Next specify the Pod Selector and (optionally) Container for the hook. These define which pod(s) the hook will apply to and which container the hooks command(s) will run in. Labels are used to identify the pod(s) where the command will be executed. If multiple labels are specified, they all must match the pod’s labels. The command(s) will be executed on all matching pods. If the container name is not supplied, the first container in the pod will be used. The template sets these to “app=mongo” and “Default” (empty) respectively. These will work for this MongoDB backup example but may need to be edited for other configurations.
Enter a suitable name for the MongoDB backup App Hook and then save it.
Create a post-backup hook that will unlock the MongoDB tables after a PV snapshot has been taken by CloudCasa. Follow the same steps as above but choose the template mongo-post-backup-system-hook.
Taking a MongoDB Backup with App Hooks
Let’s define a Kubernetes backup with App Hooks included.
- Go to the CloudCasa Dashboard and click on “Define Backup”.
- Enter a backup name, choose the cluster, and click on “Next”
- Choose either the full cluster or the namespace your database if running in, and toggle on the “Enable App Hooks” and “Include Persistent Volumes” options.
- Add the Pre and Post App Hooks you defined above as shown below.
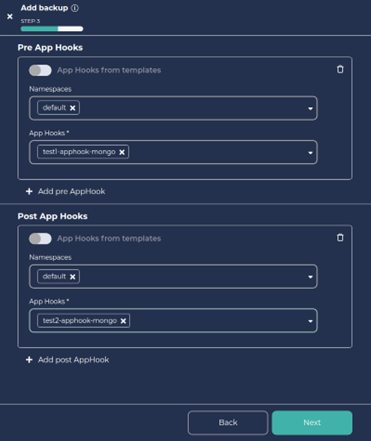
5. Click on Next and again click on Next.
6. Enter the retention days as per your need, toggle Run Now on, and click on “Create”.
7. Tracking Backup Status
a. You can track the Backup Activity in the Activity Panel of the Dashboard.
b. You will be able to see the activity details and logs by clicking on the Job name.

That’s it! We have now got a successful backup! Also, you can find the processLogs.txt file in the pod’s default directory.
Fun Fact: The name of the database was derived from the word humongous to represent the idea of supporting large amounts of data. Merriman and Horowitz helped form 10Gen Inc. in 2007 to commercialize MongoDB and related software. The company was renamed MongoDB Inc.
Simulating MongoDB Data Loss
As summarized before, there are several common causes of data loss with MongoDB on Kubernetes. These include power failures, hardware failures, and software bugs. Other potential causes of data loss include user errors, such as accidentally deleting important data, and security breaches such as hacking attacks.
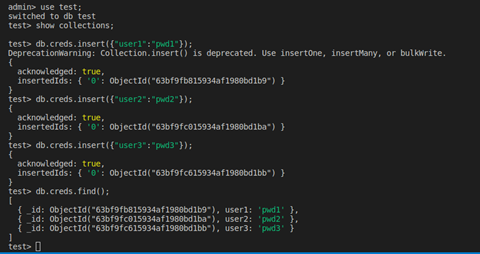
In our example, let’s delete some rows from the table to demonstrate a data loss event:
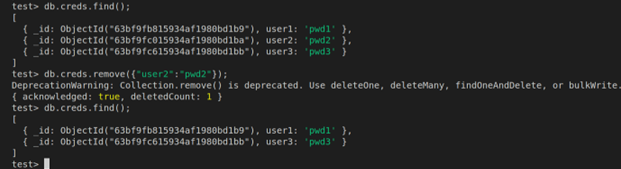
As we can see, we no longer have the row (user2, pwd2) in our table.
Now let’s try to restore the lost data.
Restoring Data From the MongoDB Backup
- On the Dashboard, find the MongoDB Backup Job you just created. Click on the Restore button.
- Choose the Recovery Point from the panel. Click on Next.
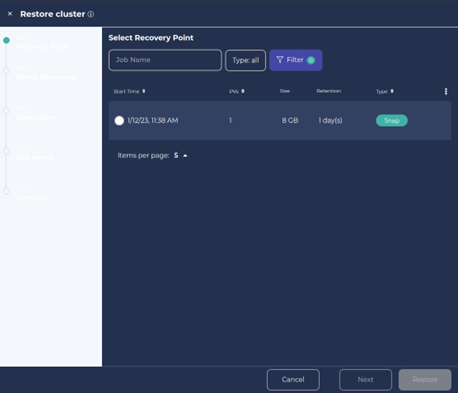
3. Select Namespace and click Next.
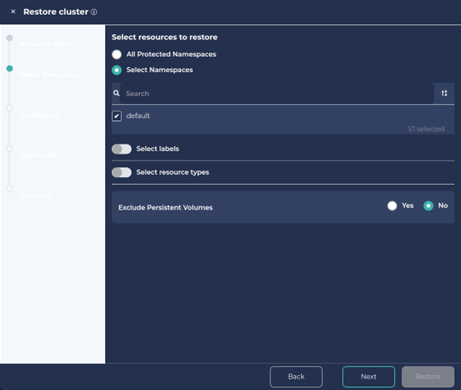
4. We can also create a new cluster or namespace with the restore.
To create a new namespace, click on ‘Rename namespaces’, add a preferred prefix/suffix and Click Next and Next.
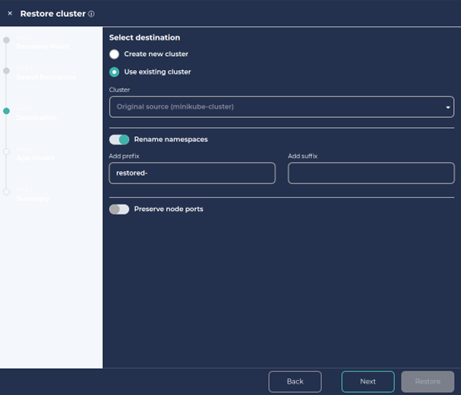
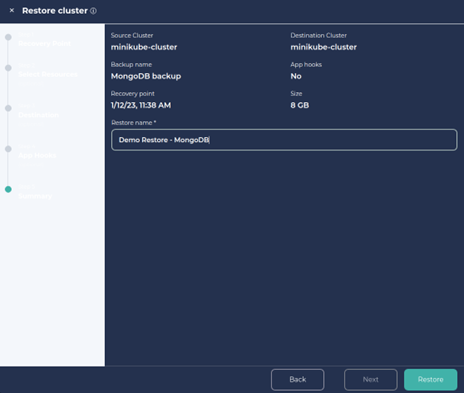
5. Provide a Job name for the restore and click on Restore.
6. You can track the restore progress in the Activity panel in the dashboard.

7. Let’s check if we have our deleted data back.
Note: As we had chosen to restore the data in a new namespace, we need to track down the new namespace.
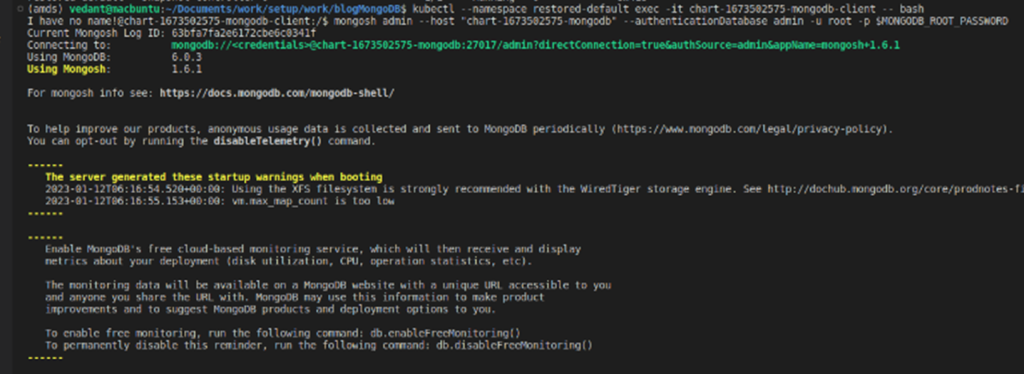
8. We can see from the above screenshot that we have the deleted rows back with us from the MongoDB backup.
Take a Victory Lap
We just saw how easy and straightforward it is to do a MongoDB backup and restore to protect your Kubernetes databases using CloudCasa. This is just a fraction of what CloudCasa does.
Indeed, CloudCasa is a powerful and easy-to-use Kubernetes backup service for DevOps, Platform Engineering, and IT Ops teams, that is fully integrated with Azure Kubernetes Service (AKS), Amazon EKS (Elastic Kubernetes Service), and Google Kubernetes Engine (GKE), as well as supporting all other major distributions and managed services and provides several amazing features like auto-scaling and multi-cloud Kubernetes backup and Any2Cloud recovery.
Sign up for the free service plan and give it a try!