
What is Autoscaling in Kubernetes?
Companies often see seasonal business spikes with periods of increased on-line demand or activity. To meet the changing application demands, Kubernetes has become the platform of choice to automatically scale web applications and infrastructure up and down. Autoscaling in Kubernetes adjusts the resources that are available to run the application or service, while minimizing the cost of those resources. Much of the success of Kubernetes is its seamless integration of cluster autoscaling with high availability. However, high availability is not data protection – it does not protect your applications and their data against cyber-attacks, accidental deletion, or data loss. This blog covers how you can preserve and customize your node group cluster autoscaling configurations during Kubernetes recovery in EKS, AKS and GKE.
Kubernetes cluster autoscaling is a cloud automation capability which relieves you of having to manually re-provision and scale up or down resources as demand changes. Without it, one needs manual provisioning of resources every time conditions change, which might not allow optimal resource utilization and cloud spending. There are actually three autoscaling features for Kubernetes: Horizontal Pod Autoscaler, Vertical Pod Autoscaler, and Cluster Autoscaler.
Why Cluster Autoscaling Matters for Kubernetes Recovery?
A key element of Kubernetes cluster autoscaling is managing node groups. Node groups are an abstraction in the Cluster Autoscaler and cluster API. Nodes in a group might share labels and taints, while still retaining the flexibility of more than one availability zone or instance type. Managed node groups in public clouds typically automate the provisioning and lifecycle management of nodes (EC2, Azure VMs, or GCE VMs.)
Pod autoscaler configurations are stored in the cluster and are usually captured by all data protection solutions and are preserved during recovery. The Cluster Autoscaler configuration is usually setup outside the cluster through the facilities provided by EKS, AKS and GKE. The autoscaler configuration data is not typically captured by Kubernetes backup and recovery solutions. CloudCasa integrates with the managed Kubernetes services (EKS, AKS and GKE) so that these cloud configurations are also captured and preserved during data migration and recovery.
Should I always preserve my node group auto-scaling parameters? No, not always. There will be times a user may prefer to create a copy of the production environment for test/dev and staging, where one may want to assign lower resources than what was assigned to production Kubernetes clusters. In such cases, an option to tune these values during cluster recovery becomes equally important.
Cluster Autoscaling Cost Savings Example
Let us go through an example where cluster autoscaling can optimize both availability and cost, or a balance of both. Cluster node sizing and cluster sprawl and are some of the biggest problems in DevOps.
For the cost comparison example, we will use GKE Standard Node Pool running 24×7 (as of Nov 29, 22)
Cluster Details: Region: lowa
Cloud Provider: GCP
Instance type: n1-standard-1

For example, an application in production has a 7-node cluster, and suddenly there is a spike in the traffic load. To avoid downtime, they need to move to a 9-node cluster. To ensure that things never go down, the application could maintain the 9-node cluster indefinitely and it would cost them 29% more for this setup. Conversely, if cluster never scaled down back to steady state, they would be overpaying by the same amount.
If a user wishes to create a test environment based on a backup done by CloudCasa of their production environment, they may expect to see much lower utilization and only need a 3-node cluster. A 3-node cluster costs the user only 33% of a 9-node cluster. By tailoring the test setup to their needs, CloudCasa can effectively reduce their test cluster costs by 67%.
Creating Clusters During Kubernetes Recovery
If everything is working fine, data protection does not get much of our attention. But with increasing cyberattacks and AI generated code entering production, application resiliency or bringing the application back online rapidly is a key requirement. In addition to data loss and recovery, most organizations are in the early stage of digital transformation where the final state of applications and infrastructure is still fluid. This fluidity creates challenges to migrate data and applications between cloud accounts, cloud providers, availability zones, regions, and networks.
CloudCasa is unique among Kubernetes backup, migration and Kubernetes app mobility solutions with its ability to create the necessary Kubernetes clusters on the fly during a recovery. Users do not have to know how to manually set up and configure their backup clusters. CloudCasa automates the cluster recovery process using the cloud and cluster configuration information from the cloud account integrations. This gives them the benefit of spinning up new EKS, AKS, or GKE clusters that mirror the original ones, and restore their data without having to do any extra manual work.
When a cluster in one of these cloud services is backed up by CloudCasa in the Activity log below, you can see the backup job collecting configuration and metadata information in addition to the Kubernetes resources and persistent volumes in your cluster.
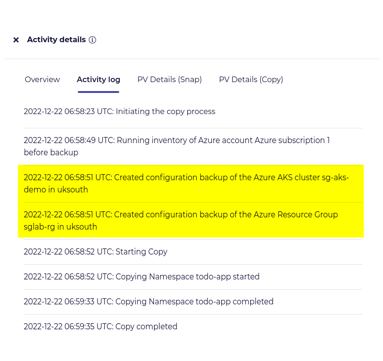
The captured information in the backup includes the networking setup, enabled add-ons, node groups and network configuration. With that configuration available when a user defines a restore, they can select an option to create a new cluster and be prompted to customize these options.
Users can then create new AKS, EKS, or GKE clusters during data recovery or data migration even if the source Kubernetes cluster is an on-premises cluster or hosted in different private or public cloud. Per the screenshot below, when restoring a cluster, the option to create a new one is available along with the type of cluster to create.
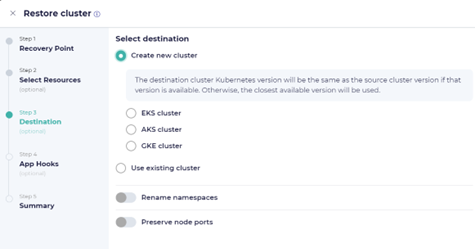
Enabling Cluster Autoscaling During Kubernetes Recovery
If a user has multiple cloud accounts or multiple projects, many of the backed-up configurations could be preserved when performing recoveries within the same cloud provider. All cloud providers suggest using different accounts and projects for test/dev, staging, and production, and this becomes unavoidable when you are migrating data and applications.
The following screenshot contains the options available when restoring an AKS cluster, where you can customize resource groups, regions, size etc.
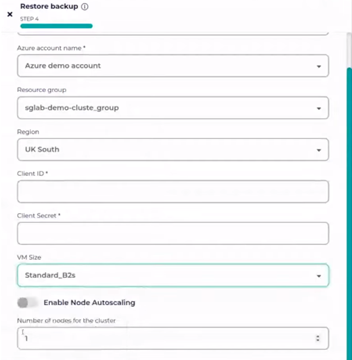
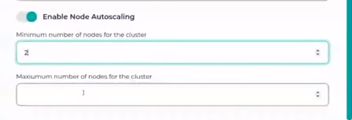
One can also see that there is an option to enable and customize node autoscaling. Combining the node size selection and the min/max/desired number of nodes in your node groups, you can size and scale your Kubernetes recovery environments just right – to your needs.
After running the restore and creating a new cluster, you can see the cluster was up and running within four minutes.
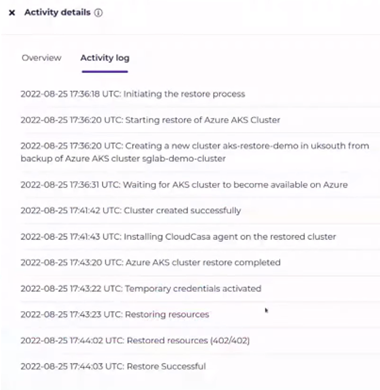
Also note that the new cluster already has a CloudCasa agent installed, and it is automatically marked as active in CloudCasa, and backup jobs can now be defined for it.
Enjoy the Cost Savings from Cluster Autoscaling
Cluster autoscaling is a core feature of Kubernetes and it is a big part of what is “managed” by managed Kubernetes services or platforms. If your cloud migration, app mobility or data protection solution ignores these capabilities, it will cost users real money as well as the time and effort needed to remedy it.
CloudCasa is built with Kubernetes to support Kubernetes backup, data migration and application mobility challenges. CloudCasa is not just cloud native but also cloud smart, which allows it to capture the full stack of your Kubernetes infrastructure and recreate it wherever you need it.
To learn more reasons why you should use CloudCasa, watch this video on the Top Five Reasons to Use CloudCasa with Azure.
You can try the free service plan for CloudCasa, no strings attached. If you want to see a custom demonstration or just have a chat with us, feel free to get in contact at casa@cloudcasa.io

