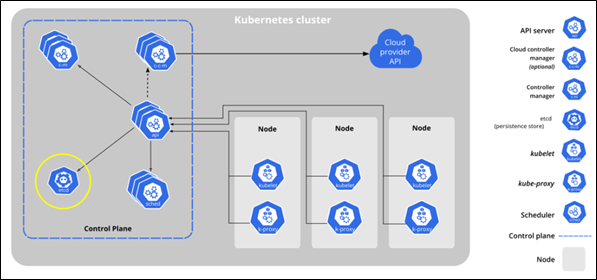
Kubernetes architecture components include the following.
- Control plane (master components)
- Kubernetes API server
- Kubernetes scheduler
- Kubernetes controller manager
- etcd
- Nodes (worker components)
- container runtime engine or docker
- Kubelet service
- Kubernetes proxy service
Based on these two main sets of components, we can categorize the data for a Kubernetes cluster as:
- Cluster resource data – etcd and other relevant configuration data such as certificates to restore the control plane
- Cloud configuration data – node pool config, load balancer info, add-ons etc.
- Persistent Volume Data – for the containerized applications running on nodes in the cluster
Why Should You Backup Kubernetes Clusters?
Initially, Kubernetes was mostly used for stateless applications with short lifespans. These were easy to develop, deploy, and retire, making them ideal for web apps or test environments.
In such cases, backing up the etcd key-value store—which resides in the control plane—was often enough to restore applications after a failure.
Today, organizations are running stateful containerized applications that manage business-critical data. This shift demands more robust backup strategies to ensure high availability and business continuity.
As access to critical data increases, minimizing downtime becomes essential. Reliable Kubernetes backup and recovery is no longer optional—it’s a requirement.
How is Traditional Backup Different from Kubernetes Cluster Backup?
Admin teams often take application-aware or crash-consistent backups of hosts or servers independently to prevent data loss or disaster.
However, using this traditional approach for Kubernetes means you’ll need separate backup mechanisms for:
The etcd database
Application data on primary storage
Persistent volume (PV) information
This might work for a single cluster, but managing backups across multiple clusters quickly becomes complex and unsustainable.
Kubernetes is inherently distributed, with applications running in containers across multiple nodes. Effective backup solutions must understand:
What constitutes a Kubernetes app
Its underlying storage
Resources like pods, nodes, and namespaces
Kubernetes also includes abstraction layers such as:
Persistent Volumes (PVs) for storage
Secrets, service accounts, and deployments for managing access and communication between containers
Traditional backup tools lack Kubernetes awareness. They don’t recognize Kubernetes APIs or its components, so block-level snapshots can lead to incomplete restores or system crashes.
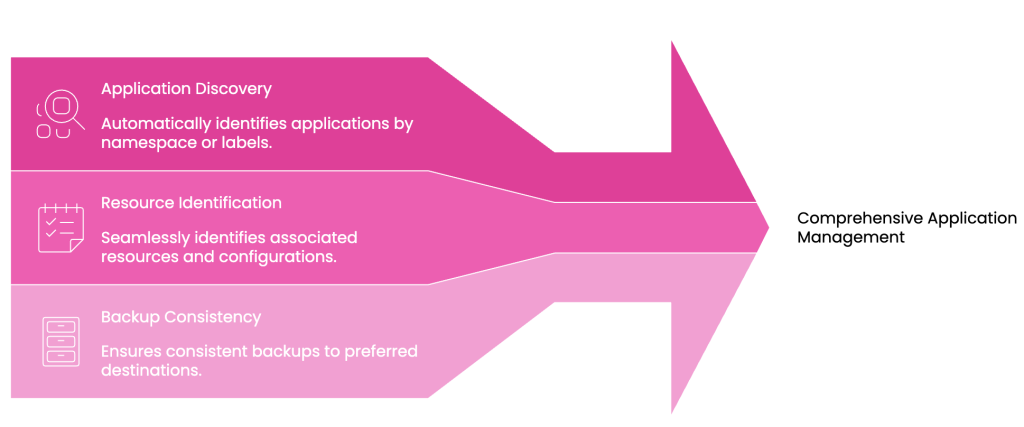
To avoid this, a Kubernetes-native data protection solution must:
Automatically discover applications by namespace or labels
Identify associated resources, volumes, and configurations
Enable consistent backups to your preferred destination
3 Ways To Protect Your Kubernetes Applications
Now that we are educated with why the Kubernetes cluster backup is important, let us understand the different methods available which help solve the challenges of Kubernetes data protection.
1) etcd and Kubernetes
Etcd is the key value datastore of the Kubernetes cluster. It is critical and a core component of the Kubernetes control plane. It stores cluster data including all Kubernetes objects such as cluster-scoped resources, deployment, and pod information. The etcd server is the only stateful component of the Kubernetes cluster and helps cloud-native applications to maintain more consistent uptime and remain working.
Since Kubernetes stores all API objects and settings on the etcd server, if your etcd data is corrupted or lost, Kubernetes cluster will not be able to continue to run. Hence backing up this storage is enough to restore the Kubernetes cluster’s state completely.
How to use etcd Backup and Restore
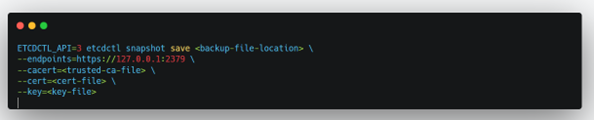
Etcd is open source and its available on GitHub and backed by the Cloud Native Computing Foundation. You can deploy the etcd database as a pod in the primary node or also deploy it externally to enable resiliency and security. In order to interact with etcd, for backup and restore purposes all commands are executed on control plane node directly using “etcdctl” command line utility. etcdctl has a snapshot option which makes it relatively easy to take a backup of the cluster.
The sample skeleton of the Backup and Restore command is as below, where v3 API (ETCDCTL_API=3) of etcdctl will be used while running the snapshot command